
Tras la introducción de Copilot, su último asistente inteligente para Windows 11, Microsoft vuelve a avanzar en la integración de la IA generativa con Windows. En la conferencia de desarrolladores Ignite 2023 en curso en Seattle, la compañía anunció una asociación con Nvidia en TensorRT-LLM que promete elevar las experiencias de los usuarios en computadoras de escritorio y portátiles con Windows con GPU RTX.
La nueva versión está configurada para introducir soporte para nuevos modelos de lenguaje grandes, lo que hace que las cargas de trabajo de IA exigentes sean más accesibles. Cabe destacar su compatibilidad con la API de chat de OpenAI, que permite la ejecución local (en lugar de en la nube) en PC y estaciones de trabajo con GPU RTX a partir de 8 GB de VRAM.
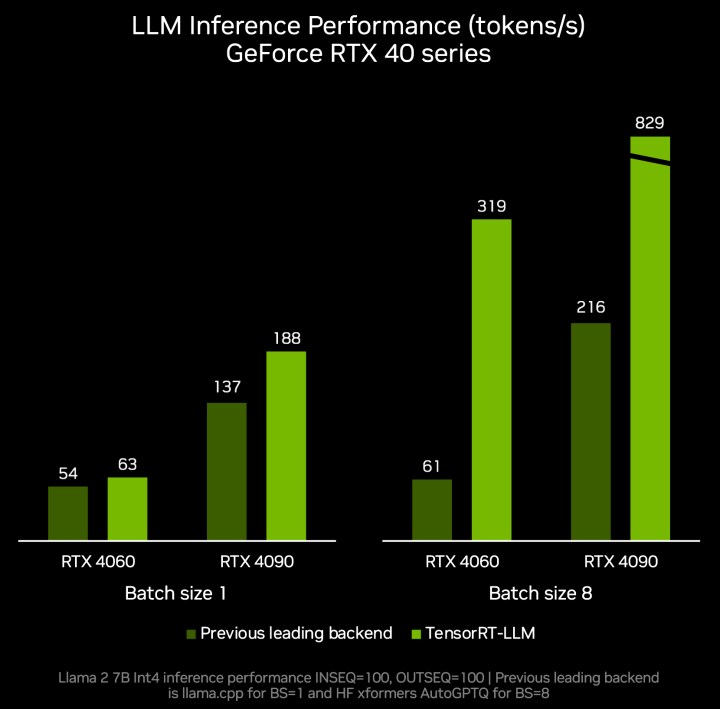
La biblioteca TensorRT-LLM de Nvidia se lanzó el mes pasado y se dice que ayuda a mejorar el rendimiento de los modelos de lenguaje grandes (LLM) que utilizan los Tensor Cores en las tarjetas gráficas RTX. Proporciona a los desarrolladores una API de Python para definir LLM y crear motores TensorRT más rápido sin un conocimiento profundo de C++ o CUDA.
Con el lanzamiento de TensorRT-LLM v0.6.0, navegar por las complejidades de los proyectos personalizados de IA generativa se simplificará gracias a la introducción de AI Workbench. Se trata de un conjunto de herramientas unificado que facilita la creación, prueba y personalización rápidas de modelos de IA generativa y LLM preentrenados. También se espera que la plataforma permita a los desarrolladores optimizar la colaboración y la implementación, asegurando un desarrollo de modelos eficiente y escalable.
Reconociendo la importancia de apoyar a los desarrolladores de IA, Nvidia y Microsoft también están lanzando mejoras de DirectML. Estas optimizaciones aceleran los modelos de IA fundamentales como Llama 2 y Stable Diffusion, lo que proporciona a los desarrolladores mayores opciones para la implementación entre proveedores y establece nuevos estándares de rendimiento.
La nueva actualización de la biblioteca TensorRT-LLM también promete una mejora sustancial en el rendimiento de la inferencia, con velocidades hasta cinco veces más rápidas. Esta actualización también amplía la compatibilidad con otros LLM populares, incluidos Mistral 7B y Nemotron-3 8B, y amplía las capacidades de los LLM locales rápidos y precisos a una gama más amplia de dispositivos portátiles de Windows.
La integración de TensorRT-LLM para Windows con la API de chat de OpenAI a través de un nuevo contenedor permitirá que cientos de proyectos y aplicaciones impulsados por IA se ejecuten localmente en PC equipadas con RTX. Esto eliminará potencialmente la necesidad de depender de los servicios en la nube y garantizará la seguridad de los datos privados y propietarios en las PC con Windows 11.



