Una increíble nueva herramienta de IA generativa acaba de lanzar Microsoft, se trata de VASA-1, un modelo de imagen a vídeo, que a partir de una sola imagen y un clip de audio, puede generar imágenes sorprendentemente realistas, con movimientos y expresiones de labios realistas.

«Presentamos VASA, un marco para generar rostros parlantes realistas de personajes virtuales con atractivas habilidades visuales afectivas (VAS), dada una única imagen estática y un clip de audio de habla. Nuestro primer modelo, VASA-1, es capaz no sólo de producir movimientos labiales exquisitamente sincronizados con el audio, sino también de capturar un amplio espectro de matices faciales y movimientos naturales de la cabeza que contribuyen a la percepción de autenticidad y vivacidad. Las principales innovaciones incluyen un modelo holístico de generación de dinámicas faciales y movimientos de la cabeza que funciona en un espacio latente facial, y el desarrollo de dicho espacio latente facial expresivo y desentrañado utilizando vídeos. Mediante experimentos exhaustivos que incluyen la evaluación con un conjunto de nuevas métricas, demostramos que nuestro método supera significativamente a los anteriores en varias dimensiones de forma exhaustiva. Nuestro método no sólo ofrece una alta calidad de vídeo con una dinámica facial y de la cabeza realista, sino que también permite la generación en línea de vídeos de 512×512 a una velocidad de hasta 40 FPS con una latencia inicial insignificante. Esto allana el camino para interactuar en tiempo real con avatares realistas que emulan los comportamientos conversacionales humanos», señala Microsoft.
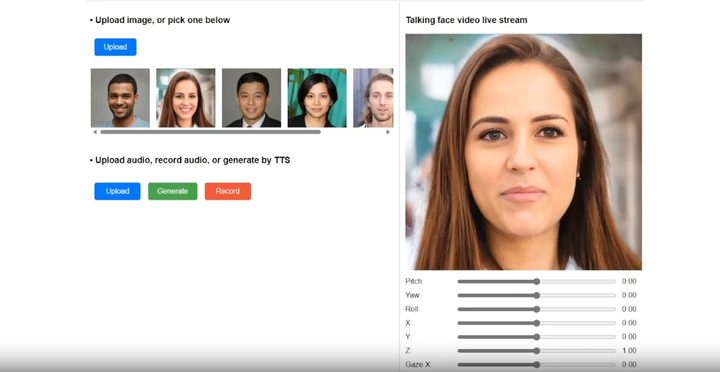
Cómo usar VASA-1
VASA-1 tienen la capacidad de manipular varios aspectos del vídeo generado, como la dirección de la mirada del personaje, la distancia percibida y el estado emocional; todo ello permite personalizar los videos para adaptarlos a necesidades específicas o efectos deseados.
Para eso, se sube una fotografía al programa, luego se añade una instrucción y un discurso de audio que se sube al sistema, se genera el video y se puede manejar la mirada, el estado de la persona, la velocidad de las palabras.