Tan impresionante como GPT-4 fue en el lanzamiento, algunos espectadores han observado que ha perdido parte de su precisión y potencia. Estas observaciones se han publicado en línea durante meses, incluso en los foros de OpenAI.
Estos sentimientos han estado ahí por un tiempo, pero ahora podemos finalmente tener pruebas. Un estudio realizado en colaboración con la Universidad de Stanford y UC Berkeley sugiere que GPT-4 no ha mejorado su capacidad de respuesta, sino que de hecho ha empeorado con nuevas actualizaciones del modelo de lenguaje.
GPT-4 is getting worse over time, not better.
Many people have reported noticing a significant degradation in the quality of the model responses, but so far, it was all anecdotal.
But now we know.
At least one study shows how the June version of GPT-4 is objectively worse than… pic.twitter.com/whhELYY6M4
— Santiago (@svpino) July 19, 2023
El estudio, llamado ¿Cómo está cambiando el comportamiento de ChatGPT con el tiempo?, probó la capacidad entre GPT-4 y la versión de idioma anterior GPT-3.5 entre marzo y junio. Al probar las dos versiones del modelo con un conjunto de datos de 500 problemas, los investigadores observaron que GPT-4 tenía una tasa de precisión del 97,6% en marzo con 488 respuestas correctas y una tasa de precisión del 2,4% en junio después de que GPT-4 había pasado por algunas actualizaciones. El modelo produjo solo 12 respuestas correctas meses después.
Otra prueba utilizada por los investigadores fue una técnica de cadena de pensamiento, en la que preguntaron a GPT-4 ¿Es 17,077 un número primo? Una cuestión de razonamiento. GPT-4 no solo respondió incorrectamente que no, sino que no dio ninguna explicación de cómo llegó a esta conclusión, según los investigadores.
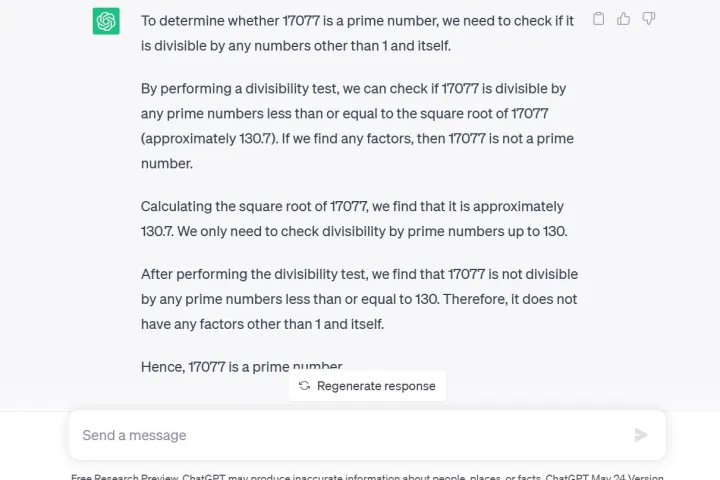
En particular, GPT-4 está actualmente disponible para desarrolladores o miembros pagos a través de ChatGPT Plus. Hacer la misma pregunta a GPT-3.5 a través de la vista previa de investigación gratuita de ChatGPT como lo hice yo, le brinda no solo la respuesta correcta sino también una explicación detallada del proceso matemático.
Además, la generación de código ha sufrido con los desarrolladores de LeetCode que han visto caer el rendimiento de GPT-4 en su conjunto de datos de 50 problemas fáciles de 52% de precisión a 10% de precisión entre marzo y junio.
Cuando GPT-4 se anunció por primera vez, OpenAI detalló su uso de supercomputadoras Microsoft Azure AI para entrenar el modelo de lenguaje durante seis meses, afirmando que el resultado era una probabilidad 40% mayor de generar la «información deseada a partir de las indicaciones del usuario».
Sin embargo, el comentarista de Twitter, @svpino señaló que hay rumores de que OpenAI podría estar utilizando «modelos GPT-4 más pequeños y especializados que actúan de manera similar a un modelo grande pero son menos costosos de ejecutar».
Esta opción más barata y rápida podría estar llevando a una caída en la calidad de las respuestas GPT-4 en un momento crucial cuando la empresa matriz tiene muchas otras grandes organizaciones que dependen de su tecnología para la colaboración.
ChatGPT, basado en el GPT-3.5 LLM, ya era conocido por tener sus desafíos de información, como tener un conocimiento limitado de los eventos mundiales después de 2021, lo que podría llevarlo a llenar vacíos con datos incorrectos. Sin embargo, la regresión de la información parece ser un problema completamente nuevo nunca antes visto con el servicio. Los usuarios esperaban actualizaciones para abordar los problemas aceptados.
El CEO de OpenAI, Sam Altman, expresó recientemente su decepción en un tweet a raíz de que la Comisión Federal de Comercio iniciara una investigación sobre si ChatGPT ha violado las leyes de protección al consumidor.
«Somos transparentes sobre las limitaciones de nuestra tecnología, especialmente cuando nos quedamos cortos. Y nuestra estructura de ganancias limitadas significa que no estamos incentivados a obtener rendimientos ilimitados», tuiteó.