¿Cómo se construye el modelo de lenguaje de DeepSeek?, ¿Necesita cierta capacidad de GPU para desarrollarse? y ¿Cómo le va contra la competencia?.
Bueno, comencemos por una definición del DeepSeek coder: DeepSeek-Coder-V2 es un modelo de lenguaje de código abierto Mixture-of-Experts (MoE) que logra un rendimiento comparable al de GPT4-Turbo en tareas específicas de código.
En concreto, DeepSeek-Coder-V2 se entrena previamente desde un punto de control intermedio de DeepSeek-V2 con 6 billones de tokens adicionales. A través de este entrenamiento previo continuo, DeepSeek-Coder-V2 mejora sustancialmente las capacidades de codificación y razonamiento matemático de DeepSeek-V2, al tiempo que mantiene un rendimiento comparable en tareas generales del lenguaje.
DeepSeek Coder comprende una serie de modelos de lenguaje de código entrenados desde cero con un 87 % de código y un 13 % de lenguaje natural en inglés y chino, con cada modelo pre entrenado en tokens 2T. Proporcionamos varios tamaños del modelo de código, que van desde las versiones 1B hasta 33B.
«Cada modelo se entrena previamente en un corpus de código a nivel de repositorio mediante el empleo de un tamaño de ventana de 16K y una tarea adicional de rellenar los espacios en blanco, lo que da como resultado modelos fundamentales (DeepSeek-Coder-Base). Ajustamos aún más el modelo base con 2 mil millones de tokens de datos de instrucción para obtener modelos ajustados a la instrucción, denominados DeepSeek-Coder-Instruct», dicen en DeepSeek.
- Entrenado previamente en 2 billones de tokens en más de 80 lenguajes de programación.
- Varios tamaños de modelo (1.3B, 5.7B, 6.7B y 33B) para cumplir con diferentes requisitos.
- Un tamaño de ventana de 16K, que admite la finalización y el relleno de código a nivel de proyecto.
- Rendimiento de última generación entre modelos de código abierto.
- Código abierto y gratuito para investigación y uso comercial.
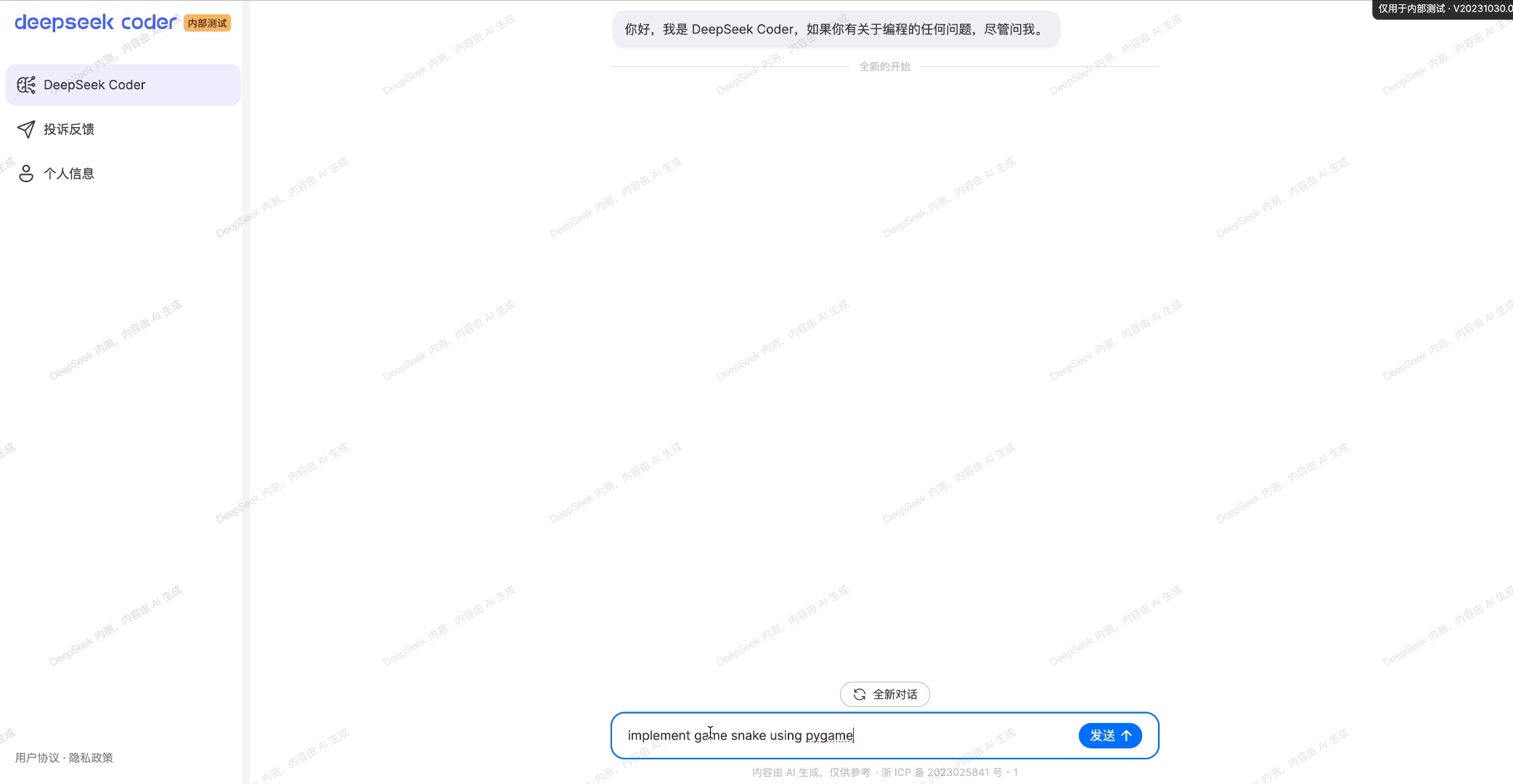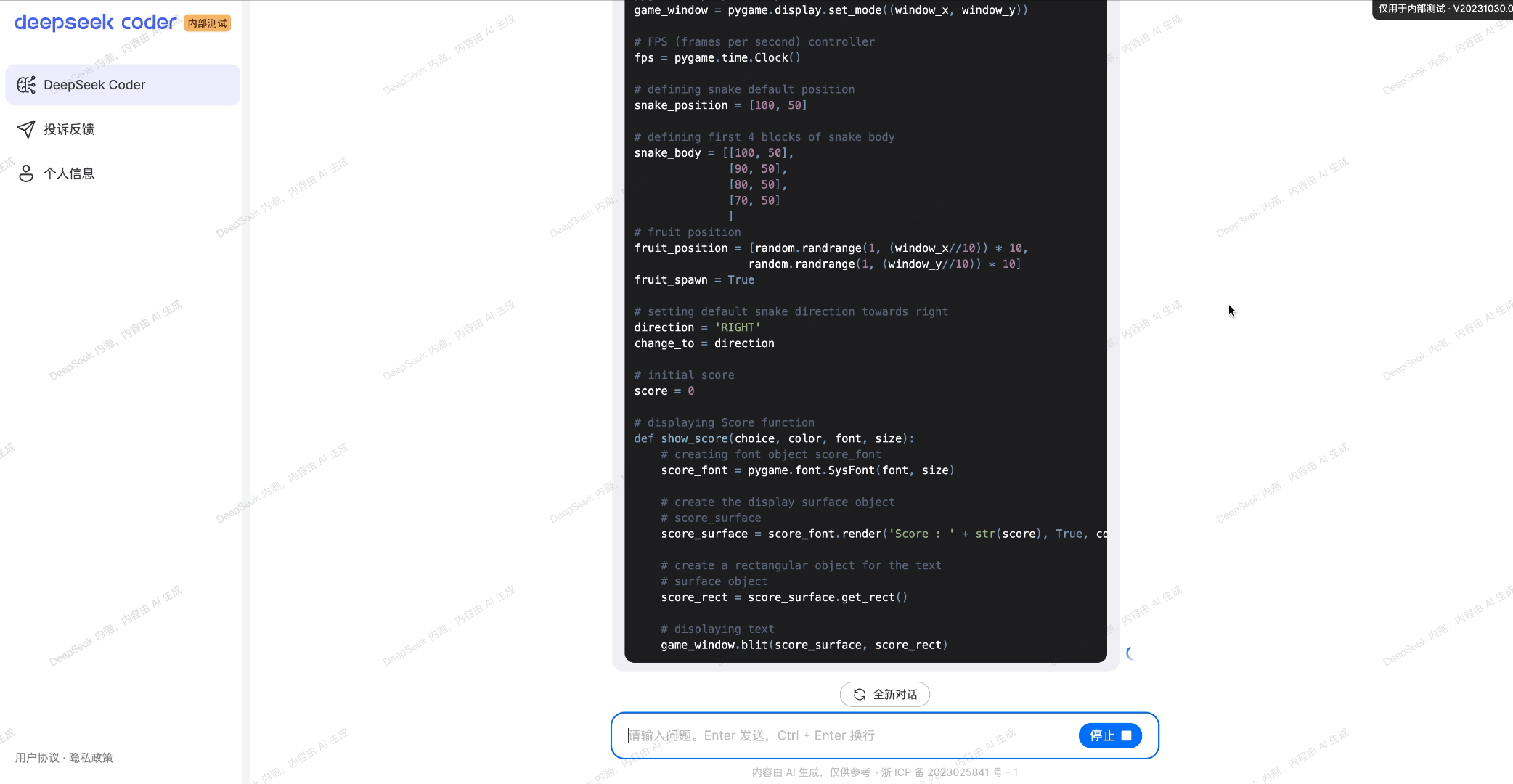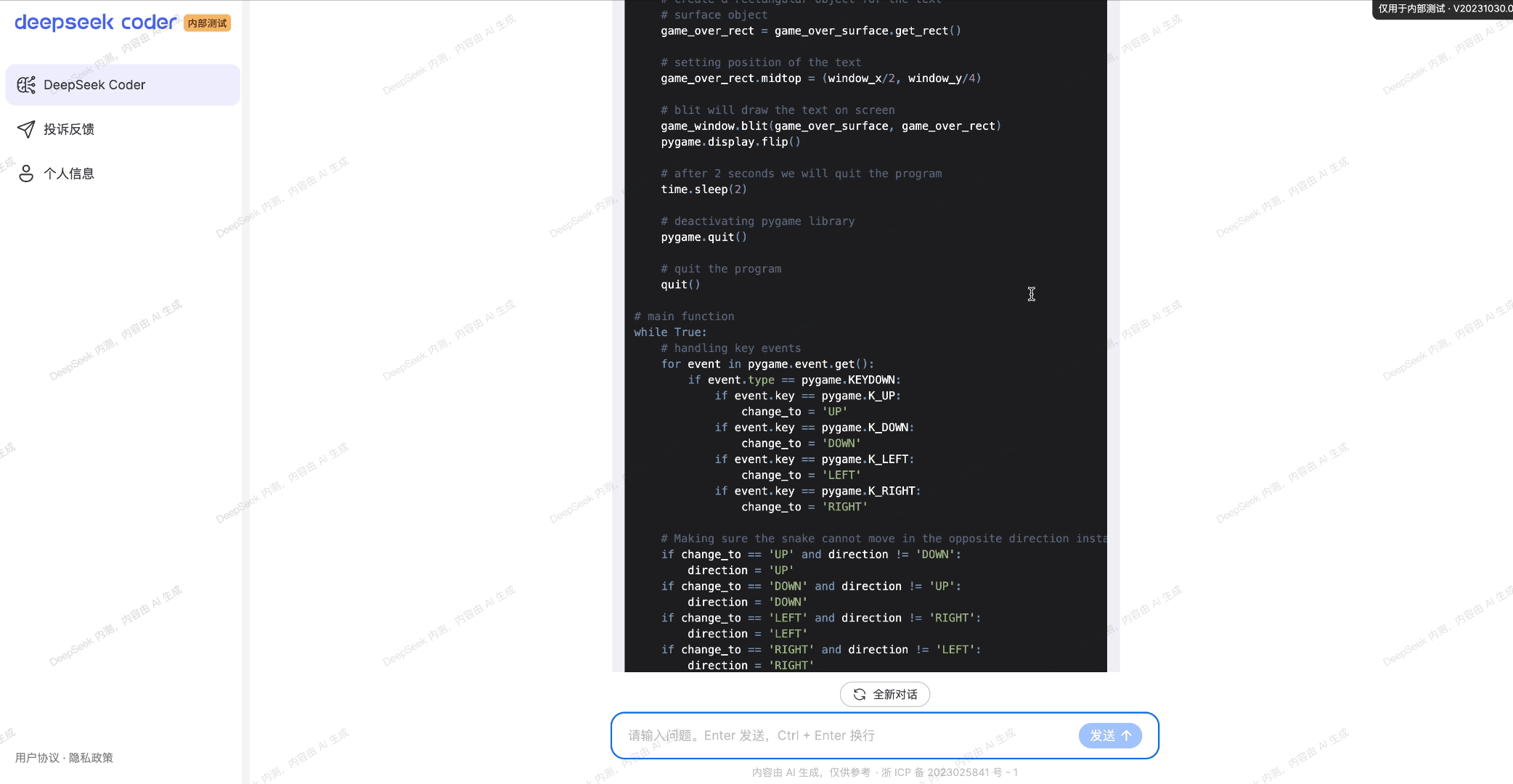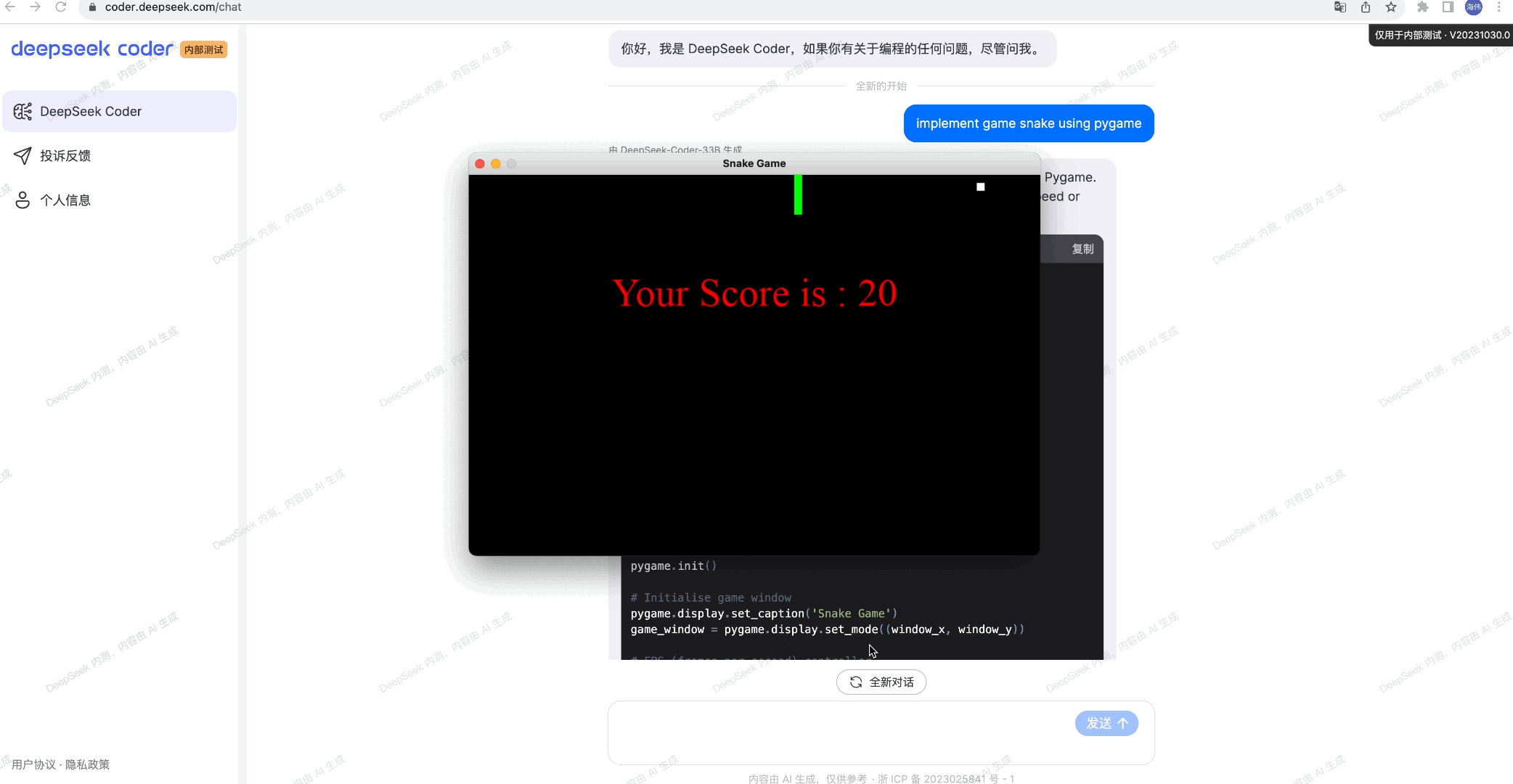
En su sitio de GitHub, DeepSeek afirma que «Si desea utilizar DeepSeek-Coder-V2 en formato BF16 para la inferencia, se requieren GPU de 80 GB*8».
Rendimiento de DeepSeek coder
En las evaluaciones de referencia estándar, y según ellos mismos muestran, DeepSeek-Coder-V2 logra un rendimiento superior en comparación con los modelos de código cerrado como GPT4-Turbo, Claude 3 Opus y Gemini 1.5 Pro en las pruebas comparativas de codificación y matemáticas:

«DeepSeek-Coder-V2 demuestra avances significativos en varios aspectos de las tareas relacionadas con el código, así como en el razonamiento y las capacidades generales. Además, DeepSeek-Coder-V2 amplía su compatibilidad con lenguajes de programación de 86 a 338, al tiempo que amplía la longitud del contexto de 16K a 128K», dice la compañía china.
ACÁ EL CÓDIGO EN GITHUB DE DEEPSEEK
ACÁ EL CÓDIGO EN GITHUB DE DEEPSEEK